予測の過程を知ることができる
「説明可能なAI」のメリットを体験しよう
予測の計算過程や重要な仮説を知ることができる「説明可能AI」
現代社会では、AIを使ってビッグデータを分析し業務の改善などに利用する動きが加速しています。
一方で、AIを使いたいけれど、少量のデータしか収集できていない方もいらっしゃると思います。しかし、近年話題のDeep Learningでは、少なくとも数千件から数万件のデータがないと、予測精度が上がらないと言われています。データ数が少ない状況では、AIの予測をうのみにするのではなく、予測結果や予測の過程を確認することが必要です。
これを行うためには、Wide Learning™のような「説明可能AI」が適しています。
Wide Learning™は、データセットから重要な仮説をもれなく発見し、それぞれに重要度を与えることで予測を行います。このため、途中の計算過程や最終判断の根拠を論理的かつ客観的に理解しやすいという特徴をもちます。これらの特徴は、判断根拠が明らかではない「ブラックボックス」なAIにはないメリットです。
具体的には、Wide Learning™を用いることで以下のようなプロセスでデータの分析や予測モデルの改善を行うことができます。
- 予測根拠の解釈
- データに潜む重要な性質の発見
- 予測モデルの妥当性の判断
- 予測を向上させるための改良方針の検討
この記事では、哺乳類判別という少量データセットの分類事例を用いて、上記のプロセスを具体的に解説します。
検証:常に正しいとは限らないAIの予測
今回の実験では、事例紹介でも紹介した哺乳類判別のデータセットを少しだけ調整したものを用います。
リンク先のファイルをダウンロードして、当サイト内のTrialToolにてご利用ください。
哺乳類判別の学習用データ: 例外「ハリモグラ」を含まないデータ(animals_train_modify.csv)
哺乳類判別の予測用データ:(animals_test.csv)
新しいデータセットで学習したAIで予測してみると、結果は以下のようになりました。
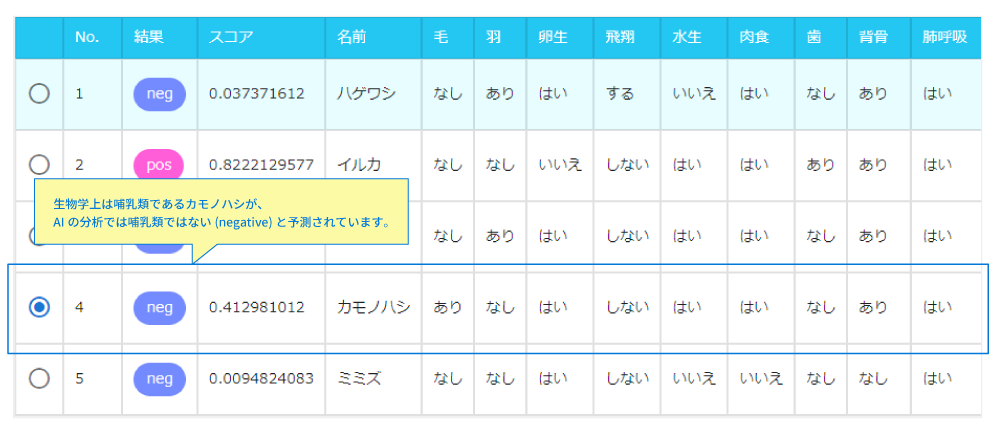
ここでは、カモノハシが哺乳類ではないと予測されています。しかし、実際にはカモノハシは哺乳類であることが知られています。なぜこのようなことが起きたのでしょうか。
解決:AIが誤った原因を分析
1.予測根拠の解釈
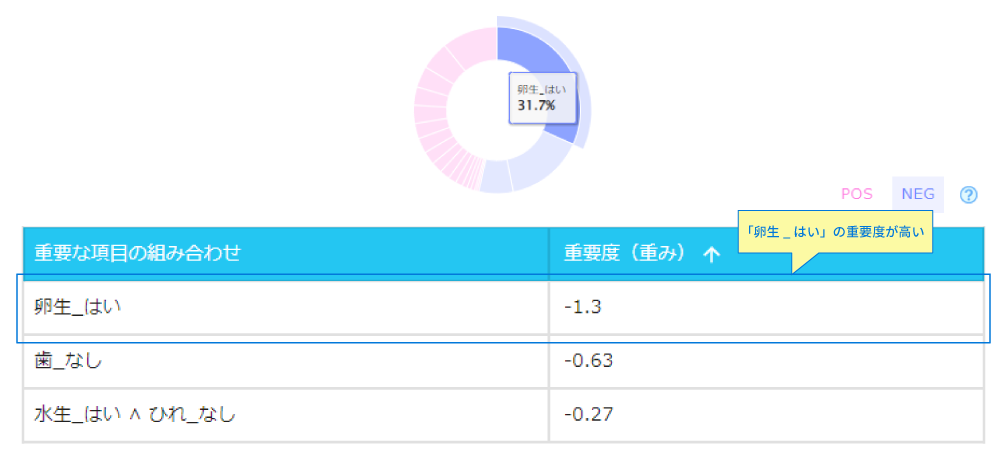
Wide Learning™はなぜカモノハシを哺乳類でないと予測したのでしょうか。「1.予測根拠の解釈」を行ってみましょう。
ここで、「重要な項目の組み合わせ」は発見された仮説を表しています。
また「重要度」はその仮説が哺乳類かどうかを判別するのにどのくらい重要な条件になるかを数値で表したものです。その値がプラスで大きな値である場合、その仮説が哺乳類だと判別するための重要な根拠になり、マイナスの値である場合、哺乳類でないと判別するための重要な根拠になります。
「卵生_はい」は、カモノハシが哺乳類でないと予測された根拠としてもっとも大きな影響を持っていると解釈できます。このことから、今後は「卵生_はい」に注目していきます。
2.データに潜む重要な性質の発見
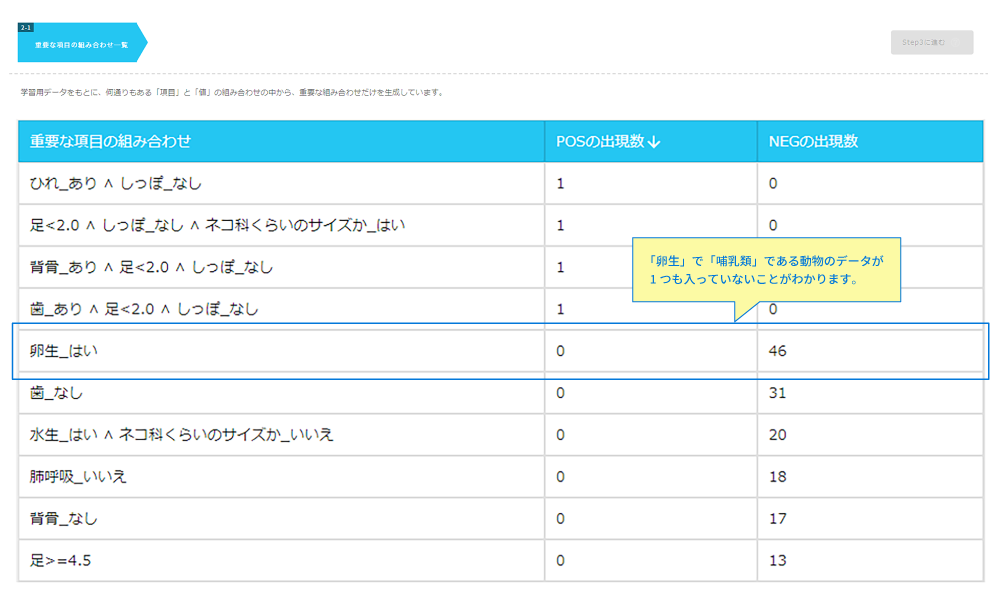
続いて、「2.データに潜む重要な性質の発見」を行っていきます。
重要な項目の組み合わせを見ると、様々な仮説が計算されています。
ここで「卵生_はい」について見ると、POS(哺乳類である)の出現数は0、 NEG(哺乳類ではない)の出現数は46です。
このことから、今回用いた学習データ上では、卵生の生物はすべて哺乳類ではないことがわかります。
3.予測モデルの妥当性の判断
ではこの予測は妥当なのでしょうか。
たしかに、卵生の生物は哺乳類ではない場合が多いですが、カモノハシのような例外も存在します。つまり、このような例外が含まれていないデータセットで学習を行ったこの予測モデルは、信頼性が低いと判断できます。
4.今後の方針の検討
最後に、今後の予測の方針を立てましょう。
ここまでの結果から、「卵生」動物についてのデータの偏りが、誤った予測を導いているのではないかと推測できます。
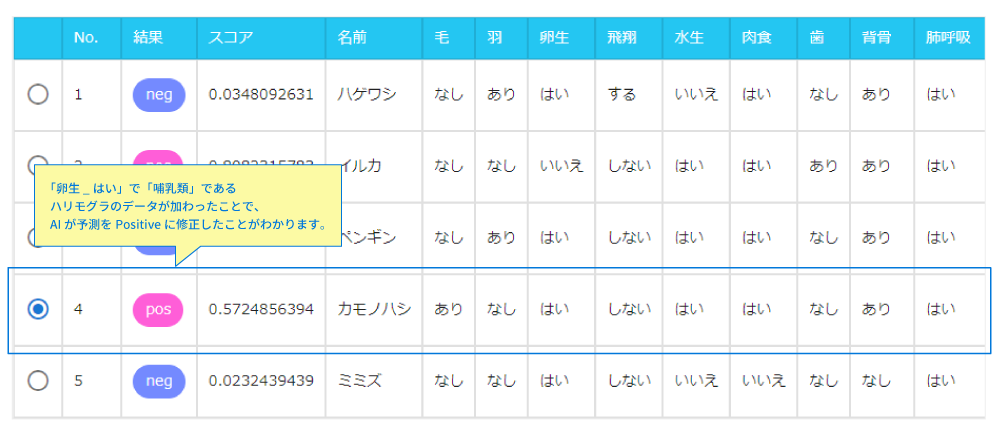
そこで、例外となる「卵生_はい」で「哺乳類」である動物のハリモグラをデータセットに加えましょう。これを用いて再学習し予測してみると、カモノハシが哺乳類であると正しく予測されていることがわかります。
下記のファイルをダウンロードして、再度当サイト内のTrialToolにてご利用ください。
哺乳類判別の学習用データ: ハリモグラを含んだ元データ(animals_train.csv)
哺乳類判別の予測用データ:(animals_test.csv)
「説明可能AI」のメリット
もし、ブラックボックスなAIだったら?
今回の実験では、最初Wide Learning™はカモノハシについて誤った予測を行いました。
しかし、Wide Learning™が出力する予測の計算過程やデータに潜む重要な仮説を見ることで、データの偏りを補正するという対処を思いつくことができました。
これが仮にブラックボックスなAIだったとしたらどうでしょう。なぜ誤ったのか、手がかりをつかむことが難しかったかもしれません。
「説明可能AI」であることのメリット
AIによる予測は、常に正しいとは限りません。
特に、少量のデータしかない状況や、データが偏っている状況では、どのようなAIを使っても正確な予測は難しいでしょう。しかし、Wide Learning™のような「説明可能AI」を用いることで、データに含まれる重要な性質の発見や、誤った予測の原因究明ができます。これが「説明可能AI」であることのメリットの一つです。





