選挙の要因の発見に挑戦
Trial Toolを使ってみよう!
哺乳類の事例では動物の情報を学習することで、哺乳類の判別を行うことができました。
ここでは選挙の当落要因の発見を行ってみましょう。
当選者の特徴は何か
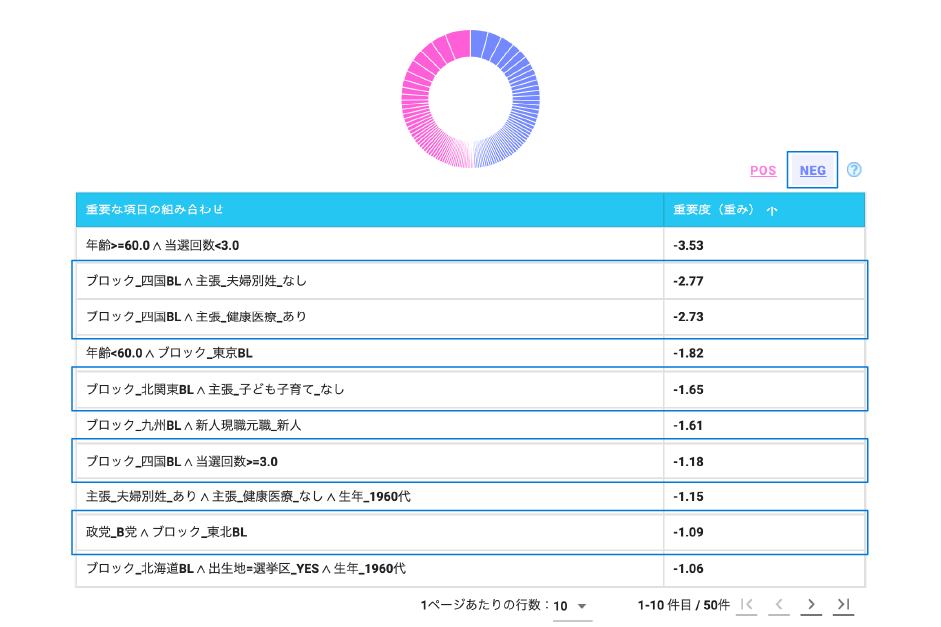
選挙で当選する候補者、落選する候補者の特徴は何でしょうか。
- どの政党に属しているのか
- 現職候補者なのか、新人の候補者なのか
- 若手なのか、重鎮なのか
- どのような政策を推しているのか
など、様々な要因が考えられます。
また、選挙は地方によって強く支持される政党が違ったりします。そういった組み合わせを1つ1つ考えて、当選に重要な要因を見つけ出すのは大変です。
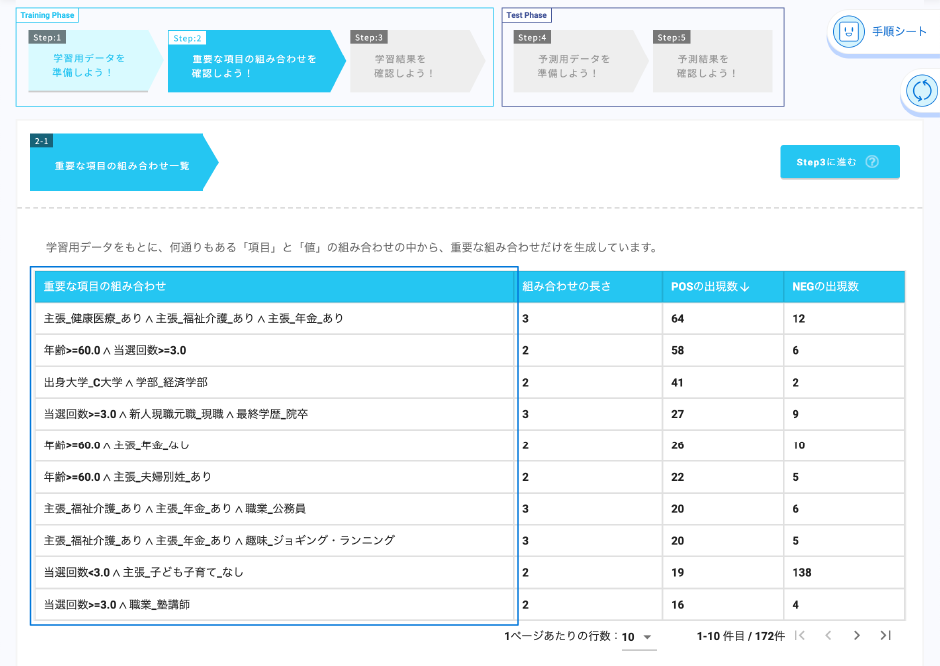
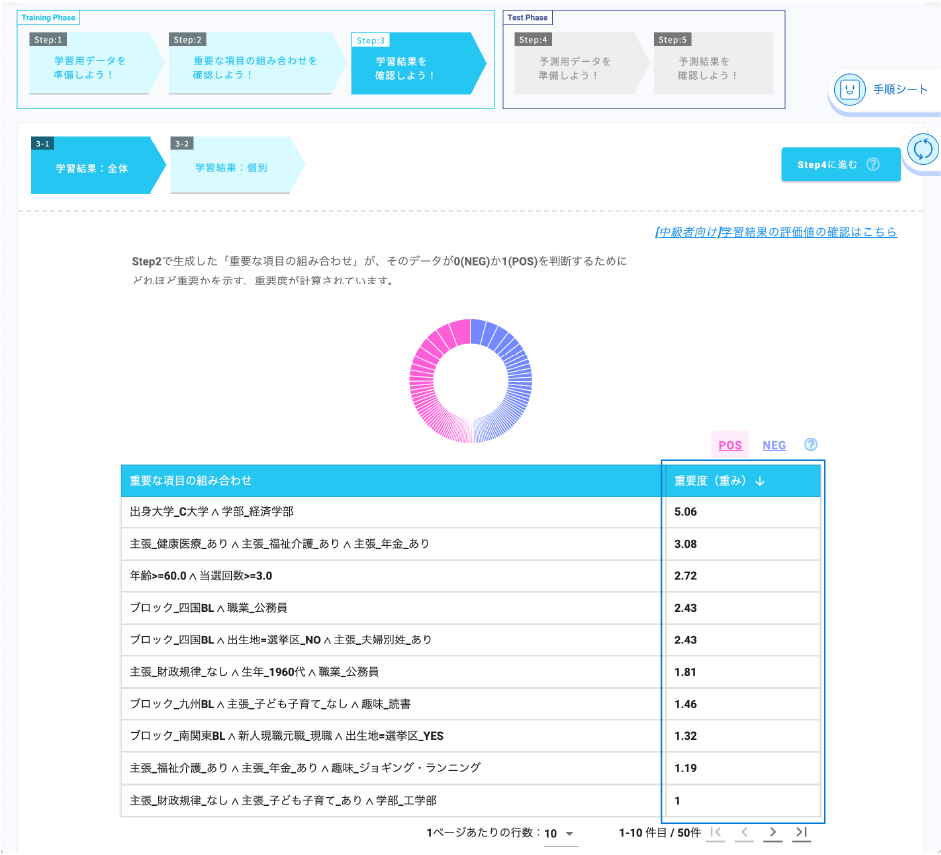
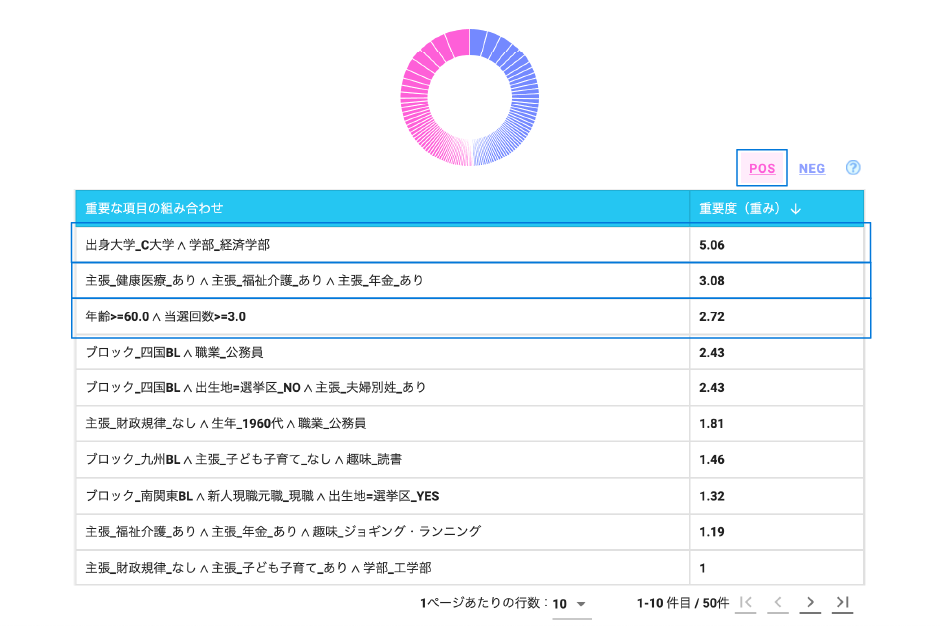
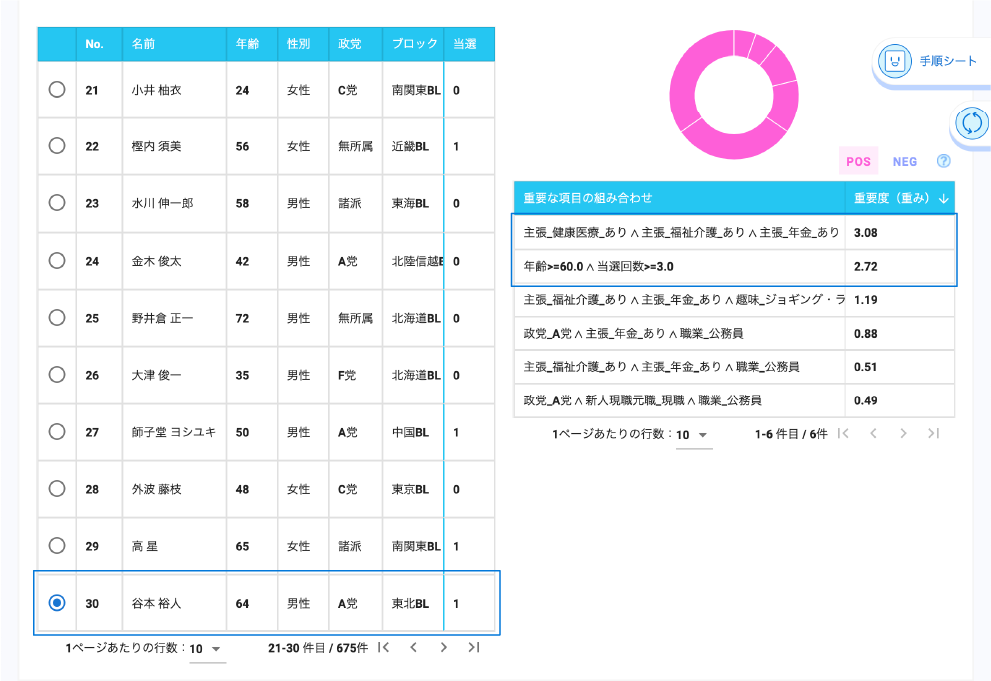
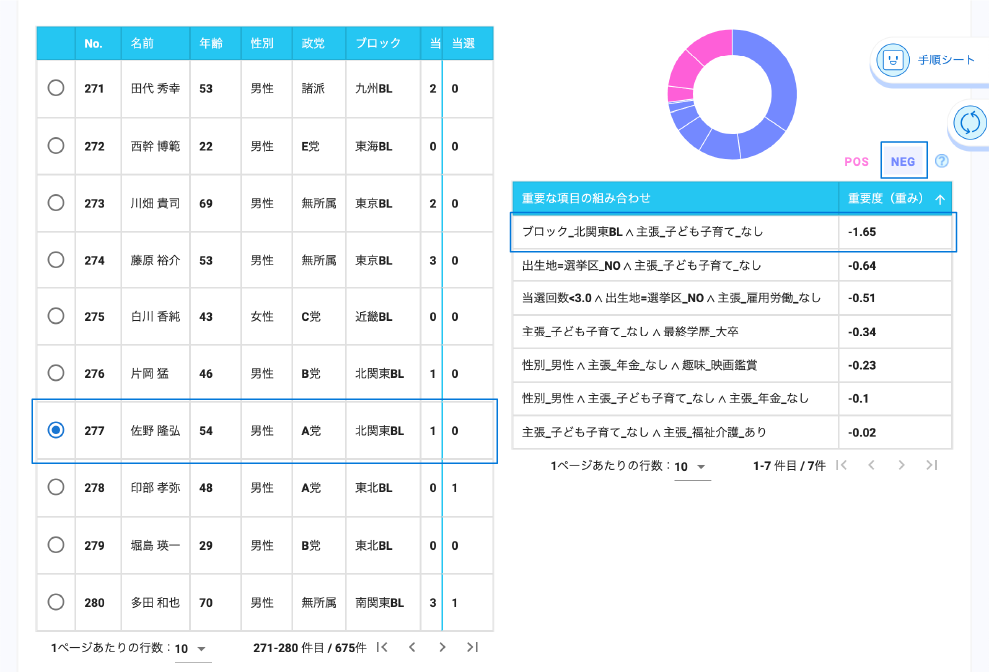
Wide Learning™を使うと、過去の選挙結果から当選において役に立つ特徴の組み合わせを簡単に見つけることができます。
そのような特徴の組み合わせを知ることで、有権者がどのような基準で投票する人を決めているかがわかり、立候補者は有権者が何を求めているのかを知ることができます。
今回使うデータ
今回、デモ用に作成したデータを使って、Wide Learning™ Trial Toolで当選者の特徴を見つけてみましょう。
Wide Learning™ Trial Toolを使って選挙当落予測行うためには、下記の2つのデータが必要ですので、リンク先のファイルをダウンロードしてご利用ください。
なお、登場する人物・団体・名称等は架空であり、実在のものとは関係ありません。
選挙事例の学習用データ:Wide Learning™に学習させるためのデータ(election_train.csv)
選挙事例の予測用データ:Wide Learning™に予測させるためのデータ(election_test.csv)
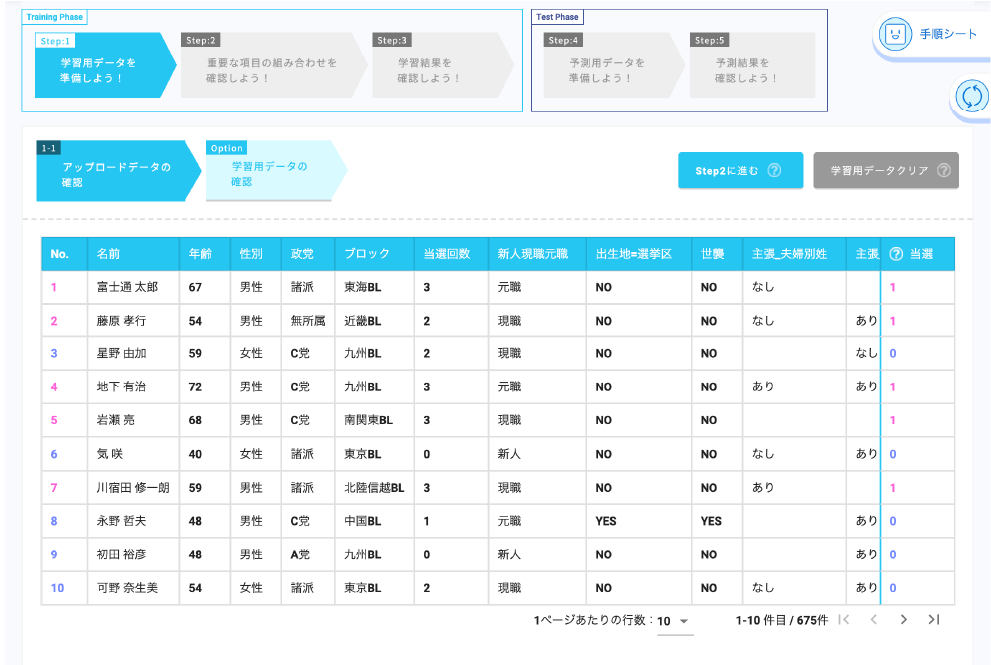
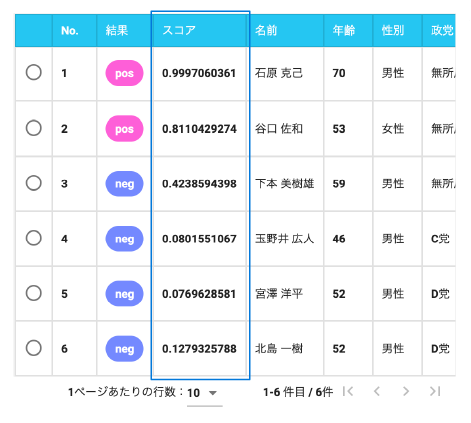
学習用データには、架空の選挙に対する当選者が219人分、落選者が456人分、合計675人分の様々な情報が表の形式で格納されています。正解ラベルである当選の列が1であれば当選、0であれば落選であることを表します。
例えば、学習用データの1行目には富士通太郎さんに関する以下のような情報が格納されています。
| 名前 | 富士通 太郎さん | 年齢 | 67歳 | |
|---|---|---|---|---|
| 性別 | 男性 | 政党 | 諸派 | |
| ブロック | 東海BL | 当選回数 | 3回 | |
| 新人現職元職 | 元職 | 出生地=選挙区 | NO |
学習用データの詳細な内容はWide Learning™ Trial Toolの「1-3. 学習用データの確認」から確認できます。